
Aurora: An innovative relational database service
本文将介绍Amazon Aurora。Aurora是AWS提供的关系型数据库服务,专门用于处理在线事务处理(OLTP)工作负载。Aurora的设计目标是提供高性能、高可用性和高可扩展性,同时保持与MySQL和PostgreSQL的兼容性。
论文参考:《Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases》
Amazon Aurora是AWS提供的一项创新型关系数据库服务,专门面向在线事务处理(OLTP)工作负载。在当今的数据处理领域,性能瓶颈已经从计算和存储转移到了网络传输上。针对这一限制,Aurora提出了全新的关系数据库架构设计。其最显著的特点是将重做日志处理推送到专门为Aurora构建的多租户扩展存储服务中。这种设计不仅减少了网络流量,还实现了快速的崩溃恢复能力,支持零数据丢失的故障转移,并提供了具有自我修复能力的容错存储系统。在技术实现上,Aurora采用了高效的异步机制,在众多存储节点之间达成持久状态的一致性,避免了传统数据库中复杂且通信频繁的恢复协议。这种创新的设计极大地提升了系统的性能和可靠性。
现代分布式云服务通过解耦计算和存储,并跨多节点复制存储来实现弹性和可扩展性。这种架构下,I/O瓶颈从单个磁盘转移到数据库层和存储层之间的网络。
数据库中的某些操作需要耗时的同步机制,这些情况会导致阻塞和上下文切换。其中一种情况是由于数据库缓冲池缓存未命中而导致的磁盘读取。读取线程必须等待读取完成才能继续。缓存未命中还可能因为需要驱逐和刷新脏缓存页以容纳新页面而产生额外的开销。一些机制(如写时复制)可以减少这些开销,但也可能导致阻塞、上下文切换和数据竞争。事务提交是另一个干扰源;一个事务提交的阻塞可能会阻碍其他事务的进展。在云规模的分布式系统中,使用多阶段同步协议(如两阶段提交)处理提交是具有挑战性的。这些协议大多不能容忍故障的发生。
Amazon Aurora是一种新的数据库服务,通过在高度分布式的云环境中更积极地利用重做日志来解决上述问题。它使用了一种新颖的面向服务的架构,包括一个多租户横向扩展存储服务,该服务抽象了一个虚拟化的分段重做日志,并与数据库实例集群松散耦合。尽管每个实例仍包含传统内核的大部分组件(查询处理器、事务、锁定、缓冲池、访问方法和撤销管理),但几个功能(如重做日志、持久化、崩溃恢复和备份/还原)被移到存储服务。具体架构如下图所示: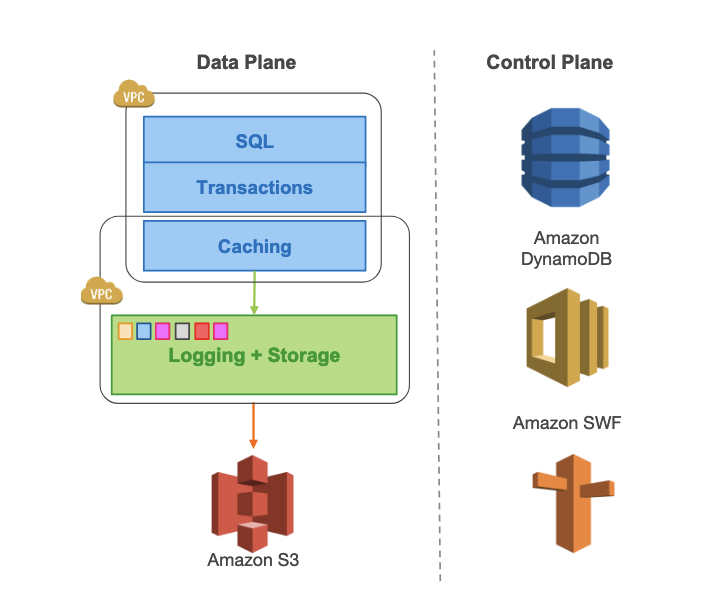
接下来将从以下几个方面介绍Aurora:
- 如何在云平台上考虑持久性,以及如何设计能够抵御相关故障的仲裁系统。
- 如何利用智能存储,将传统数据库底层四分之一的功能移动到存储层。
- 如何在分布式存储中消除多阶段同步、崩溃恢复和检查点。
持久化
数据库系统的核心功能是保证数据写入后始终可读。下面讲介绍Aurora的仲裁模型设计原理、存储分片机制,以及二者如何协同工作,在实现数据持久性、高可用性和低延迟稳定性的同时,解决超大规模存储集群的运维难题。
复制与相关故障分析
计算层与存储层的解耦
在云环境中,数据库实例(计算层)与存储节点的生命周期存在本质差异:
- 计算层:频繁因实例故障、用户主动关闭、负载弹性伸缩(如垂直扩缩容)而变动。
- 存储层:需独立于计算层实现持久化,但存储节点自身仍面临磁盘损坏、网络路径中断、硬件老化等问题。
这种解耦要求存储层必须通过跨节点复制构建容错能力。然而在超大规模分布式系统中,故障呈现以下特征:
- 持续性的背景噪音:每小时可能发生数百次节点/磁盘/网络路径的瞬时或永久故障
- 故障影响的异质性:
- 时间维度:从毫秒级网络闪断到永久性硬件损坏
- 空间维度:单个磁盘故障(影响局部) → 机架交换机故障(影响多节点) → 数据中心级灾难(如洪水、断电)
传统仲裁模型
在传统的分布式系统中,数据通常被复制到三个独立的可用区(AZ),每个AZ包含一个副本。这种设计使用2/3的仲裁规则,即写入操作需要获得至少两个副本的确认,读取操作也需要至少两个副本的确认。然而,这种设计存在一个关键的缺陷:当某个AZ发生灾难性故障时,如果其他AZ中存在独立故障,系统可能无法满足读仲裁,从而导致数据不可读。
Aurora的设计优势在于其能够应对大规模的关联性故障。通过将数据分片分布在多个AZ,并使用高密度的副本策略,系统可以在单个AZ失效时仍保持写入连续性。同时,读取操作可以从任意三个副本获取数据,结合AZ间的低延迟网络优化读取路径。这种设计不仅降低了系统的抖动,还提供了快速的自愈能力,通过持续监控副本健康状态并自动重建失效副本。
与传统的三副本模型相比,Aurora使用的六副本设计在保持相同的写入仲裁比例(66.7%)的前提下,显著提升了对大规模关联性故障的抵抗力。这种设计为云原生数据库提供了接近物理机部署的持久性保障。通过这种方式,Aurora确保了数据的持久性和可用性,同时也解决了超大规模存储集群的运维挑战。
分段存储
AWS Aurora的存储设计通过分段存储和快速修复机制来确保高持久性和可靠性。为了降低双故障叠加可用区(AZ)失效导致仲裁破坏的风险,系统将数据库卷划分为固定大小的10GB段。这些段以保护组(Protection Groups, PG)的形式进行存储,每个PG由六个10GB段组成,并跨三个AZ分布,每个AZ存储两个段。这种架构不仅提高了数据的冗余性,还将故障处理粒度细化到段级别。
在发生故障时,系统会自动监控并修复这些段。由于每个10GB段可以通过10Gbps网络在10秒内完成修复,这显著缩短了平均修复时间(Mean Time to Repair, MTTR),从而减少了暴露于双故障风险的时间窗口。数据丢失或仲裁破坏的情况发生需要满足以下条件:在同一个10秒窗口内,两个独立段发生故障,同时发生一个不包含这两个段的AZ失效。这种情况概率极低,即使面对大量数据库的管理需求,仍然可以认为风险可忽略。
此外,系统支持动态扩展存储卷,未复制情况下最大可支持64TB。这种分段存储策略不仅优化了故障恢复效率,还通过降低MTTR而非单纯减少故障率,进一步提升了AZ+1架构的可靠性,为客户提供了高耐久性的数据存储服务。





