
MapReduce浅析
本文将详细介绍由Google提出的一种用于大规模数据集并行处理的编程模型和计算框架——MapReduce,该框架目前已经很少被用在生产环境中,但其背后的基本思想仍然在现代大数据处理技术中占有重要地位
论文参考:《MapReduce: Simplified Data Processing on Large Clusters》
MapReduce框架
MapReduce是一个用于处理和生成大数据集的编程模型和相关实现。采用这个框架编写的程序会自动并行化,并在一个大规模的集群上运行。在大量数据集的处理过程中,用户只需指定相关的Map函数和Reduce函数,而无需关心框架背后的集群化处理过程。换句话说,用户可以像处理少量数据那样直接写处理函数(Map和Reduce),而无需关心背后集群到底将这些函数部署在集群中那个节点上或分配几个集群节点来运行这个函数。
Map函数和Reduce函数
使用Map函数和Reduce函数的思想来源于:在绝大部分的数据处理过程中,我们都需要将输入的逻辑记录应用Map操作,生成一个键/值对形式的中间数据,然后对所有的键/值对应用Reduce操作来合并这些中间数据,以生成合适的最终结果。例如,我们需要统计大量文本中的单词数量(这个例子非常适合并行化处理),并输出最终的结果,那么代码结构就会像下面这样:
1 | map(String key, String value): |
其中,map函数中的key为输入文件的名称,values为文件内容。map函数将输入文件中的单词都处理为如(w, “1”)这样的键值对形式,map函数会将所有key相同的中间数据组合到一起形成一个list,并将其作为中间数据提交给Reduce函数,reduce函数接收每个形如(key,list())的中间数据,并计算最终的结果,在这个例子中,reduce函数只需要计算与每个key关联的list列表的长度即可,因为map只是将形如(w, “1”)这样的键值对数据中值追加到了list中,每个值都是1。所以,MapReduce框架的数据处理过程如下:
map(k1, v1) -> list(k2, v2)
reduce(k2, list(v2)) -> list(v2)
MapReduce框架工作流程
工作流程图如下: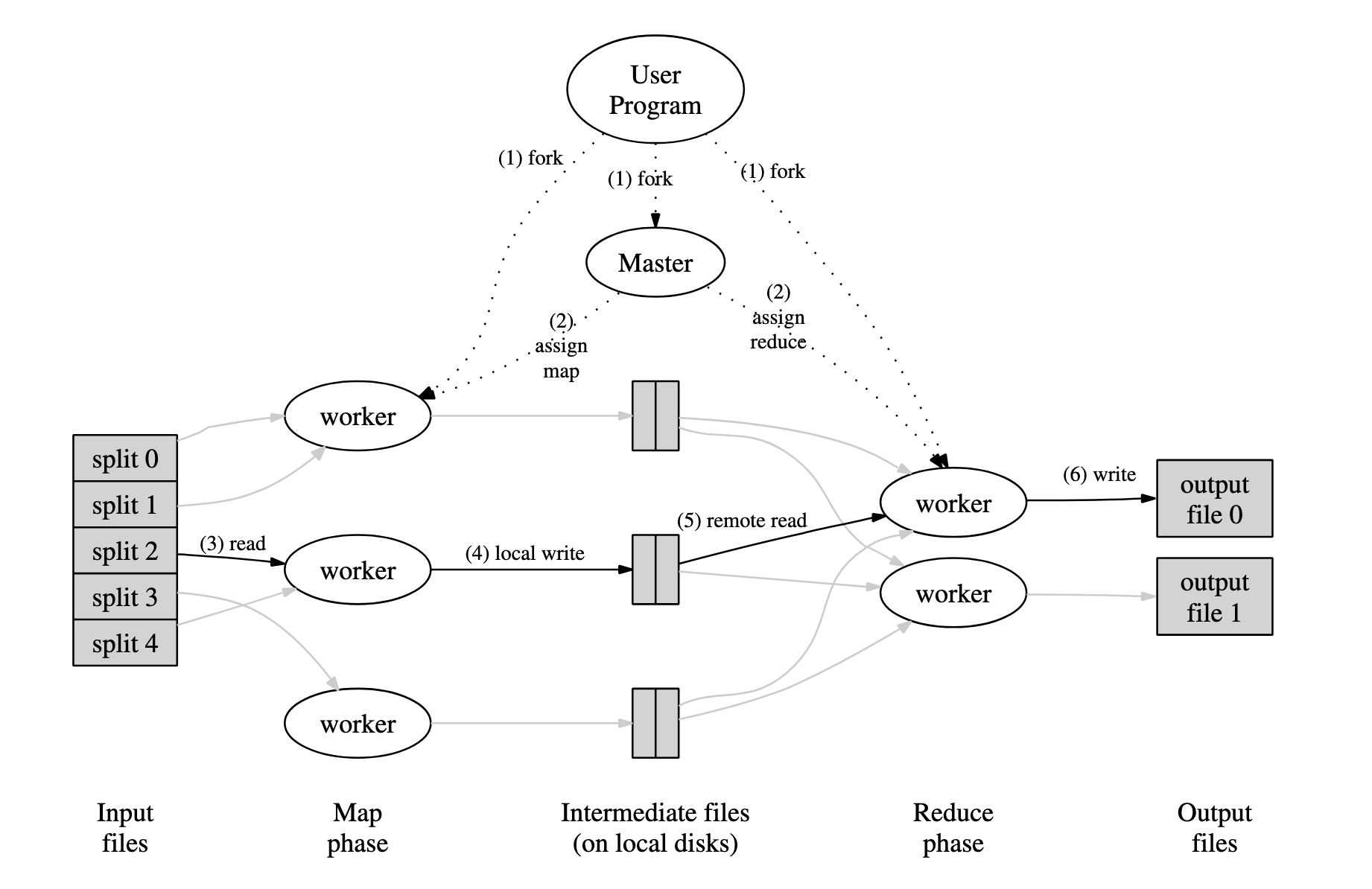
工作流程:
- MapReduce库将用户输入的文件分割为M块,每块的大小通常为16MB~64MB(通过用户参数控制),然后在集群机器中启动一些程序副本。
- 在这些运行副本的机器中,有一个机器比较特殊,他被叫做主节点(master),其余节点被称为工作节点(worker)。主节点分配工作给工作节点,并进行工作负载的调度。
- 每个被分配了任务的工作节点读取输入,并从输入中解析出键值对,将其传入用户定义的Map函数,Map函数处理产生中间数据,这些中间数据会被缓存到内存中。
- 内存中的缓存数据会被定期的写入磁盘之中,并通过分区函数将其分为R个区块(这里的R是Reduce Worker的数量)。这些缓存的中间数据的存储位置会传回主节点,主节点将这些存储位置发送给执行Reduce函数的worker。
- Reduce Worker在得到这些位置后,会使用RPC(远程过程调用)从Map Worker的本地磁盘中读取这些中间数据。Reduce Worker会按照中间键对这些数据进行排序,以便将键相同的数据组织在一起。排序过程是必要的,当数据量太大而无法直接放入内存时可以使用外部排序。
- reduce worker遍历排序后的中间数据,并且将遇到的每个唯一中间键和其值传递给用户定义的Reduce函数,Reduce函数的输出被追加到该Reduce Worker的最终输出文件中。
- 所有的map任务和Reduce任务在集群中完成后,master会唤醒用户程序,对MapReduce的调用返回。
最终对MapReduce调用的输出结果会被存储在R个文件中。通常这R个文件不会被合并,因为它们很可能会是下一个分布式过程的输入数据。
master节点的数据结构
在这个框架中,主节点需要维护大量的数据结构,对每一个分配给worker的map task和reduce task,master都需要维护他们的状态,以及他们所运行机器的ID。同时,主节点会维护每个中间数据的存储位置及其大小,并将其发送给每个Reduce Worker。
分区函数(Partition Function)
用户可以通过参数R来指定Reduce任务或输出文件的数量,数据通过分区函数划分到这些任务中。默认的分区函数是一个hash函数,操作如下:
1 | hash(key) mod R |
这样的划分通常是足够随机的,但是这样的划分方式会导致一个问题,可能会将我们需要聚集到一起的数据分散到不同的节点上。例如:有时我们希望输出的键是URL,所以我们希望同一hostname下的所有条目全部都被分配到同一文件中。为了支持这种特殊情况,MapReduce库的使用者可以提供一个特殊的分区函数。例如在上面这个例子中,分区函数可以是以下形式:
1 | hash(hostname(urlkey)) mod R |
使用这个分区函数,就可以使所有hostname下的条目最终被分配到同一文件中。
错误容忍(Fault Tolerance)
在大集群中运行的过程都需要考虑出现错误的情况,这是不可避免的,比如集群中的部分集群出现损坏或磁盘损坏等。因此,像这些分布式的过程都需要优雅的容忍机器故障。
worker出错(Worker Failure)
master会周期的ping每个worker,如果master没有收到回应,则将该节点的状态置为失败,同时所有分配给他的任务都会被重置为初始状态并等待调度。
已经完成的map任务会被重新执行一遍,因为这个worker产生的中间数据被存储在他自己的磁盘中,这些数据是无法被master访问到的。已经完成的reduce任务无需重新执行,因为它的输出结果在集群全局的文件系统中。
当有worker在执行map任务的过程中被master标记为失败,那么所有执行reduce任务的worker都会被通知重新执行,确保数据读取过程不会出错。
master出错(Master Failure)
对master节点而言,它会周期的存储CheckPoint,来优雅的应对可能会出现的变故。
原子操作来避免可能会发生的数据冲突
map函数和reduce函数产生的输出都会被原子的写入到文件中,以防race condition的发生。
性能优化
数据本地化(Locality)
网络带宽通常是构建大规模集群的性能瓶颈,MapReduce通过GFS文件系统来管理输入数据,这些输入数据被分成64MB的块,同时在集群中存在他们的三个副本。master节点负责管理输入文件的位置信息,它会首先尝试在该文件存在的机器上调度map task,如果不成功,则尝试在task的输入数据副本“附近”的机器上调度这个任务(例如,在与包含数据的机器位于同一网络交换机上的工作机器上)。在集群中的大规模MapReduce操作运行时,大多数输入数据都在本地读取,不消耗网络带宽。
任务备份(Backup Tasks)
MapReduce方案的另一个性能瓶颈就是系统中的“拖延者”(straggler),也就是那些执行map函数或reduce函数非常慢的机器。例如,某些机器上的硬盘损坏使其硬盘读写速度大幅度下降,或者在这台机器上调度了过多的任务,导致它的执行时间变慢。这时master节点在整个MapReduce操作快要完成时,备份执行剩余的正在执行的任务。无论是备份的任务或者原本的任务,只要其中之一完成就将这个任务标记为完成。这种方法可以有效的减少系统中的straggler。
结合函数(Combiner Function)
在某些情况下,经过map函数操作后,可能会存在很多重复的中间数据,并且用户指定的Reduce函数需要将这些重复的中间数据组合在一起。例如,在我们上面提到的单词计数的程序,由于单词出现的频率往往服从Zipf分布,所以每个map函数产生的中间数据中可能会包含大量的形如(the, 1)这样的中间数据,而这些大量的数据都需要占用带宽通过网络发送给Reduce Worker,由Reduce Worker来计算单词的总数,这个过程会产生资源浪费。所以MapReduce框架允许用户指定一个Combiner 函数,在数据被发送到网络之前对数据进行初步的整合。
Combiner Function在每个Map Worker上运行,它通常拥有和Reduce函数相同的处理过程,只是最后的输出位置不同。Reduce函数将输出写入到最终的输出文件,这些输出文件别集群的文件系统管理;Combiner Function将输出写入到中间数据文件并最终发送给Reduce Worker。初步的整合可以显著的加快MapReduce的处理速度。
总结
MapReduce旨在通过并行和分布式的方式处理大规模数据集。它特别适合高效处理大量数据,是大数据处理的基石技术,尤其是在 Apache Hadoop 生态系统中。如今,他也被应用在机器学习等领域。MapReduce 提供了一种强大的模型,通过利用分布式计算资源来高效的处理大规模数据集。本文并未全面的探讨MapReduce框架,只是提供了一些基本的概念,如有兴趣,请参加其论文原文和具体代码实现。






